Improving the Wait for LLM Inference with Server Sent Events (SSE)
The quality of waiting is one of the most important features to consider when developing software UX. Like most engineering products, when waiting is skillfully managed, users won’t notice it at all. When executed poorly, it becomes a cultural touchstone (see: Pinwheel of Death). This is especially true on the modern web, where competition for attention is higher than ever. Bounce rates increase dramatically with longer waits. New frontend frameworks are developed to shave milliseconds off latency. So it is ironic that Large Language Models (LLMs), the most compelling new software technology in years, introduce a lot more waiting.
Introducing ChatCPG
Late in 2022, Tickr started developing LLM workflows that are tuned to perform data analysis for CPG clients. We named the product ChatCPG.
The first iteration of the ChatCPG front-end used RESTful HTTP requests to communicate with the server. A user would select filters and click a button to launch an analysis. This would send a request to the server which would retrieve and process the relevant data, pipe that data through our LLM, and return the response—a complete report on historic sales, competitor sales, category inflation, and forecasted sales. Insightful summaries were generated by the LLM on each component of the report and actionable recommendations were suggested.
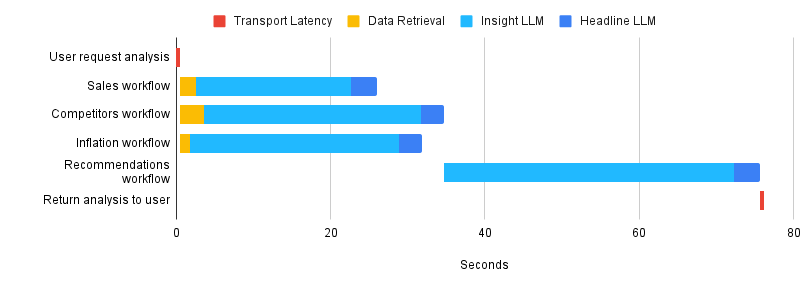
Figure 1 illustrates the components of ChatCPG’s Optimize Pricing workflow and how each contributes to the overall wait time. First, the user’s request for an analysis travels from the client to the server. Next, three workflows—Sales, Competitors, and Inflation—run in parallel. The responses from these workflows are inputs for the Recommendations workflow. All four of these component workflows are composed of an Insight and a Headline workflow which must run in series. When the Recommendations workflow is complete, all of the response data can be returned to the client. The entire process took almost 75 seconds.
The content of the final report was impressive, but the wait was too long. 75 seconds is an eternity in a web application. The magic of interacting with the LLM was lost.
Figure 1: ChatCPG’s Optimize Pricing workflow latency with a single HTTP request
UX Benefits of Streaming
An overlooked contributor to the success of OpenAI’s ChatGPT is the quality of the streaming response interface. The obvious benefit of streaming text is that the user’s brain stays engaged with the product during LLM response generation. Instead of waiting for a large block of text, the user can begin reading the response as soon as possible.
There is another important, subtle benefit. Watching the output of the model stream into the client creates the feeling that you are interacting with an intelligent assistant. That you are watching something or someone think and create. You feel like you are in collaboration.
This is an important illusion. The first result of an LLM response is rarely perfect. But it is often closer to the user’s desired result than a blank page, and this spurs the user to iterate their prompt or edit the response forming a virtuous cycle of creativity between the user and the LLM.
In The Design of Everyday Things, Dan Norman quotes MIT professor Erik Brynjolfsson:
The best chess player in the world today is not a computer or a human but a team of humans and computers working together. In freestyle chess competitions, where teams of humans and computers compete, the winners tend not to be the teams with the most powerful computers or the best chess players. The winning teams are able to leverage the unique skills of humans and computers to work together.*
With ChatCPG, Tickr is not seeking to replace CPG analysts. Instead, we’re building an AI-powered tool that analysts can use to leverage their domain expertise into prescriptive solutions in a fraction of the time compared to existing workflows. To best facilitate machine-human collaboration, we concluded that streaming LLM responses to the user as soon as the first response token was generated should be an early feature of ChatCPG.
** Erik Brynjolfsson made this statement about a decade before the computer chess engine Stockfish started dominating chess championships without human intervention. However, chess is a closed system with a set of clearly defined rules. For open ended problem solving that requires complex strategic thinking, the human brain is still a powerful contributor. Even in the example of chess, it took decades of human interaction with the engines themselves for the engines to reach their current prowess.*
What are we waiting for?
In addition to the transport latency and data processing time associated with an HTTP request, LLM products have to cope with inference latency: the cost of producing a result from a trained model. A deep dive on inference latency from Databricks provides this formula:
Latency = Time To First Token (TTFT) + Time Per Output Token (TPOT) * Number of Output Tokens
TTFT is governed by the input length of the query. With ChatCPG, we are operating at the upper bounds of the input length of available models in order to produce the highest quality analysis from the most context.
The fastest we could display a response token is the sum of the roundtrip transport latency, data retrieval, and the TTFT.
The overall inference latency will be governed by the length of the output since TPOT, although smaller than TTFT, is multiplied by the number of output tokens. As an example, as of December 2023, ChatGPT-4 can be set to a maximum of 8,192 output tokens. The goal is to make this phase of the wait less noticeable to the user by streaming tokens into the client as they are generated.
Choosing a Streaming Technology: Server Sent Events (SSE)
We considered several technologies for streaming: HTTP polling, WebSocket API, and Server Sent Events.
HTTP polling requires the client to send requests at a regular interval, retrieving any updates on the server since the last poll. We considered this to be a brute force solution that results in many unnecessary requests, since the client is sending requests without knowing the frequency of available updates. Polling is also a brittle solution. The ideal polling time will change as models evolve and TPOT varies.
The WebSocket API is a powerful technology for enabling two-way communication between a client and server. Most common use cases involve sending low-latency updates from one user to another in collaborative applications or multiplayer games. However, scaling the WebSocket API adds complexity on the client and server, and the rest of our front-end product was served by simpler RESTful patterns.
Server Sent Events (SSE) use the EventSource interface to allow a client such as a browser to open a persistent connection to an HTTP server. The server can then use this connection to push updates to the client on an event-driven basis. The connection will remain open until closed by the client or server.
Historically on HTTP/1.1, users were limited to only 6 open connections per browser and domain which is an impractical limit for users that enjoy opening many tabs for the same website. However, with the advent of HTTP/2’s multiplexing over TCP, the maximum number of simultaneous HTTP streams is negotiated by the client and server and defaults to 100. Almost all modern browsers are using HTTP/2, so for an enterprise application aimed at professional users, we felt safe adopting SSE.
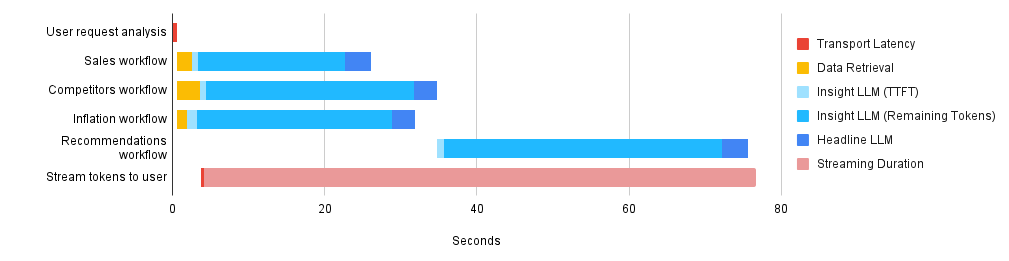
Figure 2 contains the same workflows from above, now showing TTFT and remaining token phases for each LLM workflow and demonstrating the improvement in when data is first available to the front-end—around 4 seconds, a manageable wait. The first available token benchmark could be further improved by optimizing data retrieval or TTFT of the Insight LLM workflows.
Figure 2: ChatCPG’s Optimize Pricing workflow latency with SSE
Next Time: UI Considerations
Streaming tokens to the frontend as soon as they are generated via Server Sent Events is a major infrastructural improvement to our LLM product, ChatCPG. It allows our users to stay engaged with our application during the lengthy waits associated with LLM inferences and exposes users to the magic of real-time LLM response generation.
However, the benefits of streaming responses are not automatic, and there are many potential UI pitfalls. How can we handle these rapid UI updates without frustrating or disorienting Tickr’s users? I’ll discuss several strategies in my next post.
- Publish Date
- November 24th, 2023
- Abstract
- This article emphasizes the crucial role of managing wait times in software UX design, particularly in the context of the competitive modern web where user engagement can be significantly impacted by loading delays. It highlights the irony that Large Language Models (LLMs), despite being a breakthrough in software technology, inherently introduce longer wait times, challenging traditional UX principles.
- Authors
 Will Preble
Will Preble