Creating Synthetic Data to Train Your Own LLM
Training Your Own LLM: Private, secure, and tailored
Large language models (LLMs) have shown great promise in being able to simplify business analytics workflows. Powerful third-party foundational models are being equipped to perform analytic tasks such as data cleansing, model selection and optimization, chart generation, etc. However, there are barriers that must be overcome before there is a large scale enterprise level adoption. Among these barriers are:
- Security concerns around private information being shared with a third-party LLM
- API costs associated with scaling up third-party LLM powered analytic services within an enterprise
- Training an LLM with domain specific knowledge related to your industry
All of these barriers can be addressed by training your own LLM. This process involves using an open source LLM that is hosted within your own network and trained on your own data. This article discusses our learnings from one of the initial steps required to train your own LLM—creating a training set.
Automating the Creation of a Training Set
Our objective was to train an in-house LLM capable of accurately responding to business analytics queries, leveraging data extracted directly from databases. We develop a training set comprising thousands of question-answer pairs. The traditional manual approach to generate such a dataset is not only labor-intensive but also time-prohibitive, particularly when scaled across multiple use cases and databases. To address this challenge, we developed a process for the automated creation of synthetic business question-answer pairs conditioned on a SQL database.
This effort involved deploying a method to generate a broad spectrum of questions. We then actively refined this pool of questions to distill a high-quality set of synthetic questions. The LLM is then tasked with providing accurate responses based on the associated data. Questions that are too similar or that don’t lead to clear responses are removed from the set. Our streamlined methodology marks a significant leap towards efficiency and cost saving in creating synthetic training sets across business data and ultimately setting the stage for training proprietary LLMs.
The First Challenge: Output Limits
Our first task was creating a set of diverse business questions related to our data. We provided an LLM, specifically OpenAI’s GPT-4 0613 checkpoint LLM, with the schema of our database which consisted of a file listing all the columns and tables in the database as well as some example values for each dimension. In addition, we provided the LLM with seed questions that can be answered with the data. The database includes historic sales data for hundreds of products, demographic data on the buyers, details about each product, and details about the retailer and sales channel for each sale. Table 1 below provides a few example seed questions:
Table 1: Sample Seed Questions Provided to the LLM
| Questions |
| What are the top 5 items ordered by customers who were born in California at Grocery stores in August 2022? |
| What was the total sales for the brand Cheerios at Big Box stores in June 2022? |
| What were the top 3 retailers in terms of average basket size in Jun 2022? |
| What is the average basket size for trips that include a male on the trip vs those that include a female on the trip? |
| What are the top 3 categories by total sales for households with 7 or more members in July and Aug 2022? |
To train our large language model effectively, we aimed to produce roughly 1,000 diverse questions. However, we encountered a constraint with the model’s output token limit, which capped the number of questions it could generate in a single response. Instructing the model to partition the output into smaller segments was unsuccessful, with a maximum of 150 questions generated at one time. Additionally, when we equipped the model with a tool to autonomously generate questions, the lack of variability in the questions made the results unviable.
This led us to refine our strategy. We began to make multiple requests to the model, each for 150 questions, and then compiled these questions into an aggregated collection. Indeed, If there was no output limit (or if it was 10x the current limit), the methods we describe below to create a diverse set of 1,000 questions wouldn’t be needed. The focus then shifted to ensuring the breadth of diversity in questions throughout the entire set, which presents a new challenge. We had to ensure that the aggregate list of questions maintained a high level of heterogeneity. This large list of heterogeneous questions, along with their corresponding answers, serves as the foundational dataset for training an LLM. The aim is to enable the model to accurately respond to any query similar to those in the training set while also effectively generalizing to new tasks.
The Second Challenge: Question Diversity
We found that each set of 150 questions provided by the LLM would be sufficiently diverse in isolation. However, once aggregated, many of the questions were very similar. We wanted to avoid including similar questions in the training set for two reasons:
- To ensure the broadest possible scope of questions for the training set
- To avoid artificially high performance of the model when testing on out of sample data.
To identify similar questions we converted the questions to vectors, assigned them to clusters, then performed pairwise comparisons between questions using a similarity function within each cluster of questions. If two questions were very similar, one would be removed.
We investigated a few different routes to maximize the diversity of the generated questions. First, we experimented with the source of the seed questions for each set of 150 generated questions. We tried the following methods:
- using the same seed questions for each set
- using random questions from the first set of generated questions to seed the later sets
- a multistep process that used specific questions from clustered subsets of the first set of generated questions to seed the later sets.
For method (c) above we first asked the LLM to create 150 questions based on a manually created set of 5 seed questions (the “manually generated seed questions”). We then clustered the generated set of 150 questions and for each subsequent request used a subset of these questions from one of the clusters as the new seed questions. To perform clustering, each question is converted into a series of numbers (embedding) and each question can then be thought of as a vector in a high dimensional space. Clusters are groups of questions whose vectors are generally pointing in the same direction. Each cluster therefore has a center — which is the average direction that the vectors in the cluster are pointing. We pulled out the centermost and the least centered question from each cluster. We used 10 clusters and this process resulted in 10 pairs of artificially generated seed questions that were sufficiently diverse from one another. The “diversity” of the final set of questions was measured by the percent of questions that were retained after a similarity threshold was applied to removed similar questions.
While keeping the temperature fixed, method (b) showed an 5 percentage point gain over method (a) and method (c) showed an 8 percentage point gain over method (b) in terms of the percent of questions that passed the similarity threshold test. We also experimented with adjusting the temperature during question generation, testing values in the range of .7 to 1.5. The optimal diversity of questions was found when the temperature was between 1 and 1.05 and method (c) above was used. Increasing the temperature from .7 to 1 provided the largest improvement in diversity in the final combined set of generated questions (a 19 percentage point increase in the number of questions passing the similarity threshold test). However, as we increased the temperature beyond a certain point, the questions were more likely to fail the SQL validation process, which we’ll discuss next.
Validating the Generated Questions
Once we had created a diverse set of questions, we needed to validate the questions. There were a two things to validate:
- Whether a SQL query could be generated to retrieve the appropriate data
- Whether an answer could be generated based on the retrieved data
Any question that didn’t pass the above tests was removed from the list. For the validation steps we leveraged an LLM. For the first validation, we gave each question 3 tries at creating a valid SQL query. If it failed on the first try, we sent the question, the failing SQL query, and the error response back to the LLM for another try. If this recursive process failed another two times, we removed the question from our list.
For the second validation, we sent the question and the retrieved data (obfuscated for privacy if needed) to the LLM and asked it to answer the question or respond with “fail” if it was unable to answer the question with the given data. Again, if it failed, the question was removed from our list. The validation steps for each question were processed in separate queries to avoid hitting input token limits.
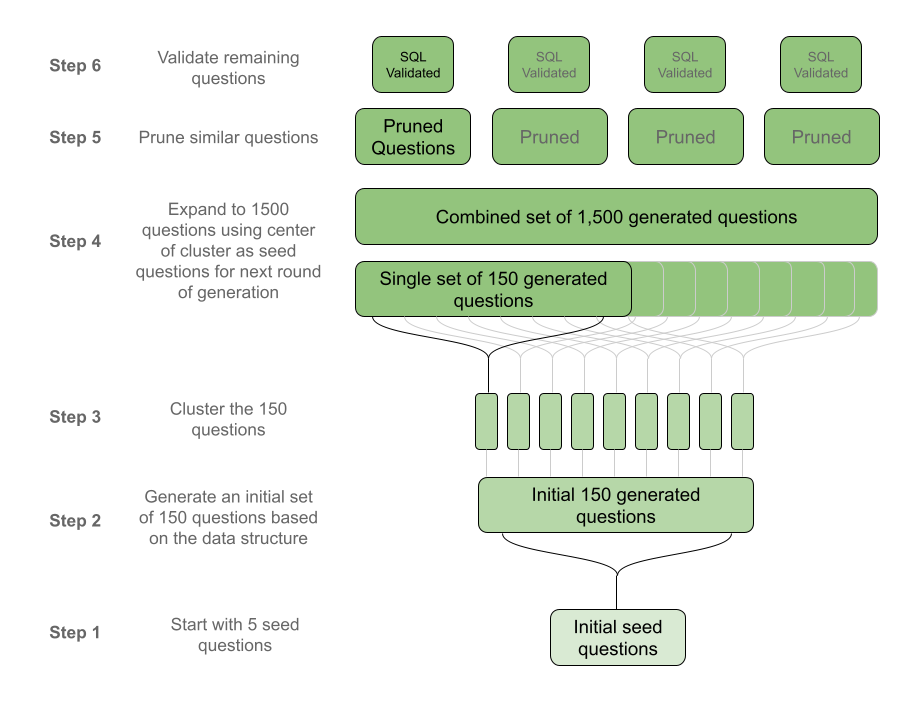
A Two Stage Process for Generating Diverse Question-Answer Pairs
Our final process included two stages:
- A “growth” stage where an LLM generates a large number of questions related to a given database structure (steps 1-4 in the diagram below)
- A “pruning” stage where the questions are validated for uniqueness and the ability to generate a valid SQL query and a response based on the data retrieved from the SQL query (steps 5 & 6 below)
These steps are similar to the “grow” and “improve” steps discussed in this August 2023 paper on Reinforced Self-Training by Google DeepMind researchers. Much like pruning a tree, if two branches (questions) were too close to one another (too similar) we’d remove one of them.
Diagram 1: Steps of the Growth and Pruning Stages
Optimizing the Process
In the end we created a process with a variety of parameters that we could tweak to optimize the quality and diversity of the final output training set. Those variables were:
- Diversity and number of initial seed questions — the more diverse the better
- Clustering Algorithm — we used spaCy for embedding and K-means for clustering
- LLM Temperature — lower than 1.0 led to many similar questions, higher than 1.05 led to too many questions that failed to produce successful SQL queries.
- The number of clusters created on the initial generated set of questions (that were then used to seed questions for the next question generation requests) - we used 10 clusters and we suspect that fewer clusters would reduce diversity in the final list (however we did not test this).
- Size of initial output — Is it always beneficial to maximize the size of the initial list of generated questions? We asked for 150 questions to be generated at once. This was the maximum allowed given output limits. We did not experiment with other values.
Results
Here are some examples of the final outputs
Table 2: Example Question-Answer Pair Results
| Question | Answer (details obfuscated for privacy) |
| What are the top 5 parent brands with the highest quantity of items sold in Apr 2022? | The top 5 parent brands with the highest quantity of items sold in Apr 2022 are:
|
| What is the age bucket of the consumer who made the highest number of transactions in Jan 2022? | The age bucket of the consumer who made the highest number of transactions in Jan 2022 is 35-44. |
| What are the top 5 brands favored by the '35-44' age group? | The top 5 brands favored by the ‘35-44’ age group are:
|
| In May 2022, how did the the total cost of purchased items across different income buckets compare? | In May 2022, the high-income bucket spent slightly less than the low-income bucket. The high-income bucket spent $23,351,150.08 while the low-income bucket spent $23,355,330.89. The mid-income bucket spent $22,304,979.97 which is less than both the high and low income buckets. The unknown income bucket spent the least, at $1,015,537.00. |
| What are the 5 most popular purchase times (day part) in Nov 2022? | The 5 most popular purchase times (day part) in Nov 2022 are:
|
| How many transactions involve both male and female adults on the trip in Mar 2023? | The number of transactions that involve both male and female adults on the trip in Mar 2023 is 1,498,788. |
After running the process multiple times, we created a validated list of 3,322 question-answer pairs. To get a rough sense of whether the questions were diverse, we enlisted two subject matter experts to create 10 “standard” business questions from the dataset and 10 “obscure” questions from the dataset. Our AI generated synthetic set contained 100% of the standard questions and 73% of the obscure questions created by the subject matter experts. Interestingly, the questions that the subject matter experts came up with that were not covered in the synthetic dataset were related to changes in complex patterns over time. For example “how have my consumers’ demographics changed over time?” or “What are the demographics of people who use to buy my product but have since moved to a competitor?”.
Our subject matter experts took 2 minutes on average to generate each question. Writing and validating the appropriate SQL query took 15 minutes per question. Writing the answer took another 2 minutes. So for one question, a human with knowledge of SQL, the database schema and CPG business concerns would take about 19 minutes. In comparison, the LLM wrote questions in 1.9 seconds, wrote and validated queries in 78.4 seconds, and wrote answers in 3.2 seconds for a total of 83.5 seconds. This is a 93.1% reduction in the time required to create a training set data.
Conclusion
Our task of creating question-answer pairs for training data was greatly accelerated by leveraging an LLM to draft most of the code, generate questions, generate SQL queries to retrieve the data, and then finally generate answers given the data. A task of multiple weeks was reduced to a few days!
Training your own LLM can provide significant cost savings, greater privacy, and better performance. Using the methods described here, an existing LLM can be leveraged to securely create a training set from any internal database. Once created, you are well on your way to having your own secure LLM optimized for your business data.
- Publish Date
- January 2nd, 2024
- Abstract
- Large language models (LLMs) have shown great promise in being able to simplify business analytics workflows. Powerful third-party foundational models are being equipped to perform analytic tasks such as data cleansing, model selection and optimization, chart generation, etc. However, there are barriers that must be overcome before there is a large scale enterprise level adoption.
- Authors
 Tim Williams
Tim Williams