Distributed Workflows at Scale
Queues are a pattern that have been used at Tickr since the early days of the company. Much of the work we do at Tickr is in the background: data retrieval, alerting, processing incoming webhooks, and many more activities that don’t follow the typical request-response pattern found in many typical applications. Often times, these tasks can be handled by background cron jobs; however, at Tickr we found that scaling this approach is painful after a certain volume of jobs. Instead, we embraced queues as a pattern for processing, managing, and tracking our background workloads.
What is a queue?
In essence, a queue is a temporary place to put messages, background jobs, or raw data. In our case, these are all background jobs. These jobs can be put into multiple channels within the queue to keep them isolated from each other, and each job can have a different priority. Pulling jobs off the queue happens one-by-one, and jobs are ordered by their priority.
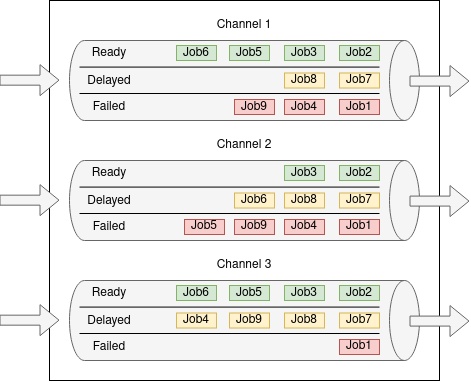
That’s it! Think of a queue as a set of pipes, with jobs going in one side of the pipes, and coming out the other in the desired order.
When a job is finished processing, it’s deleted, and the next job can be grabbed. If a job fails to process, it can be put back into the queue in its original position to be tried again. If it fails multiple times, it can be put into a separate place specifically for failed jobs, and it can be retried later. Jobs can also be set to run after a delay.
At Tickr, we use Beanstalkd for our queue dispatcher, which has been incredibly capable, fast, and reliable.
Why is this useful?
The queue gives us a coordination mechanism that organizes our background work and also gives us some key metrics that are otherwise difficult to attain:
- What needs to be done?
- How much needs to be done?
- How fast is it being done?
- Are there any failures happening?
Question 1 can be answered with many systems and isn’t particularly outstanding. Question 2 is a bit more interesting. We can, at a very quick glance, know exactly how much work is waiting to be done. Question 3 is incredibly helpful for automation, which we will talk about in a minute. Question 4 allows us to see if there are any systemic failures quickly and easily.
The metrics that answer these questions allow us to do some very interesting things with automation and scaling.
Scaling with queues
In the past, it was common to put all our jobs in just a handful of channels. We’d have what we call “workers” (a process that grabs and processes jobs) listening on those channels. These workers were static. If we needed more processing power, we’d deploy a change to increase the number of threads they could use or spin up another worker by hand.
We quickly scaled past the ability to do this effectively: some channels became consistently backed up, and keeping up with scaling the workers up and down was tiring.
This is what spurred Tickr to explore and implement container orchestration. If we had a process that could watch the queue for us, read the metrics we used to decide how to hand-scale our workers, and spin workers up or down automatically, we could scale out and scale in our workloads automatically.
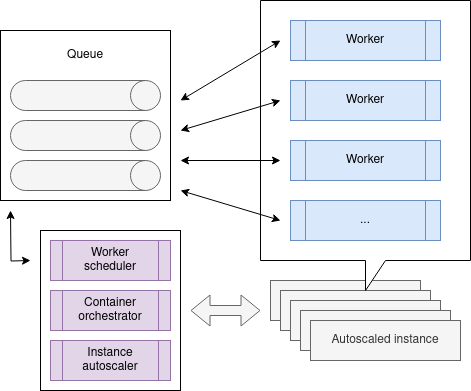
We wrote a worker scheduler that reads metrics from the queue (active channels, jobs per minute, etc) and decides what worker containers to spin up and how many. Then, the worker scheduler submits the jobs to the container orchestrator, which runs the workers on an auto-scaled set of nodes connected to the container system.
This pattern has been fantastically successful: we can at any time put jobs into any channel and, within 60 seconds, have a worker auto-created to start processing those jobs. We began segmenting our different workloads by class and subclass into different channels. This allowed us to see which classes of jobs were processing slowly or having more errors, increasing observability by leaps and bounds.
This allows for massive scale: each channel can have near-unlimited workers processing jobs simultaneously, and we can have near-unlimited channels to process jobs in. We can scale out our workloads to an incredible degree by breaking down jobs into the smallest pieces possible and letting the scheduler and auto-scaler figure out the fastest way to perform all the work.
This also helps with costs: we can run our auto-scaled queue workloads on ephemeral instances, and we only keep them around for exactly how long we need them. No more paying for servers that are idling!
Workflows
While scheduling and processing background work is intrinsically useful, another part of queues that we’ve leaned into heavily is the ability for jobs to create other jobs. In essence, we can create highly-concurrent, highly-scalable multi-step workflows.

This makes it possible to break tasks down into small, discrete steps which makes scaling out even more effective (because each job can be processed simultaneously) and also increases observability and failure handling. We can see, at the smallest level, where errors are happening or where bottlenecks are.
Rate limiting
Another great aspect to queuing is that sometimes we want certain workloads to only run at a certain rate. This can be accomplished in two ways: concurrency and rate limiting.
We limit concurrency by adjusting our worker scheduler to set an upper limit on the number of concurrent worker processes on a per-channel basis. This allows us to match certain workloads with known scaling limits in other systems.
Rate limiting is performed by using Redis as a coordination mechanism between workers, allowing us to set a number of calls per second on a per job type and per customer basis. This is fantastic when dealing with external APIs that rate limit calls or when gathering data from SQL databases that have concurrency limits.
Having these two options for limiting the flow of jobs gives Tickr incredible flexibility and observability into which APIs, customer databases, or systems need to be have their limits scaled up or down.
One last thing to mention that falls under the same umbrella as rate limiting and concurrency: pausing. We can pause any channel and immediately stop all jobs from being processed. If a particular channel or job type is causing an outage or problem, we can immediately pause it without service disruption to other parts of the system and buy ourselves time to fix the problem. The queue will happily accept new jobs into that channel, but no jobs will be processed until we’re ready to go again.
Observability
This is mentioned throughout this post, but the queue gives us incredible observability into what’s happening and what’s going wrong. But what’s better than seeing what’s happening and what’s going wrong right now? Being able to see it 30 days into the past!
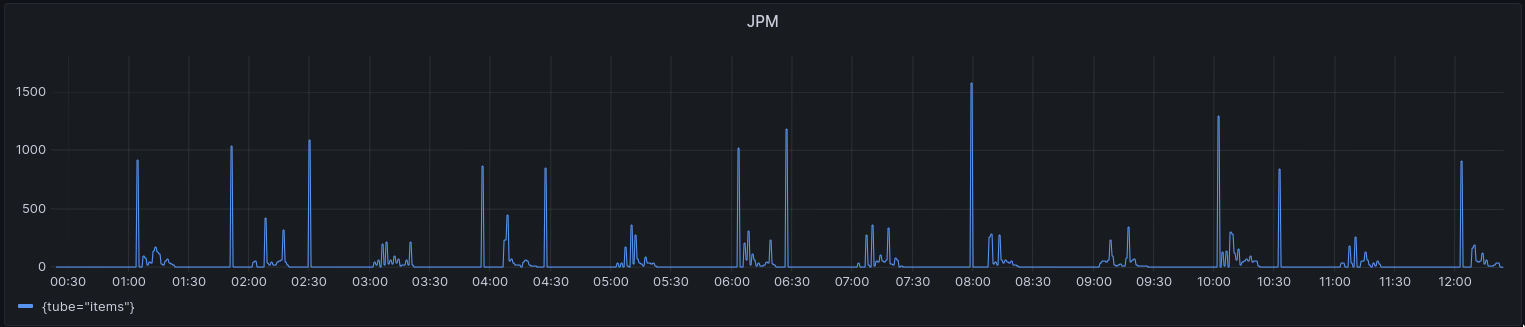
We export our queue metrics into Prometheus and can look back into the past to see what happened, when, and often times why something happened. This gives us not just job rates and failure rates but also alerting. Is a channel paused for too long? Is a channel getting backed up faster than we can process it? We send alerts for things like this, which helps us take immediate action.
This gives us an incredible high-level view of our workloads and lets us quickly debug issues within our systems.
Benchmarks
Beanstalkd runs as a single-process service (like memcached or Redis) and per a preliminary benchmark on a test instance, it processed a little over 54K jobs per second (at about 75% CPU saturation). This translates to about 195M jobs per hour, from one single test instance.
We run two instances on production servers: one with a binlog for jobs that require durability, and one in-memory instance optimized for throughput that handles more ephemeral jobs that can be easily recreated on failure. This combination gives us very good trade-offs with performance and resilience.
What’s next?
Queues have proven to be enormously beneficial at Tickr. They are perfect for background-heavy tasks, which constitute much of Tickr’s workloads. In review, queues:
- Allow for creating high-throughput workflows that can be scaled up or down automatically.
- Enable detailed monitoring and alerting to get visibility into bottlenecks, failures, or problems.
- Allow for flow control of tasks whether via rate limiting or pausing entirely.
The next post will be a more detailed look at the things we’ve built on top of our queueing system and the business problems this allows us to solve.
- Publish Date
- November 7th, 2023
- Abstract
- Queues are a pattern that have been used at Tickr since the early days of the company. Much of the work we do at Tickr is in the background: data retrieval, alerting, processing incoming webhooks, and many more activities that don't follow the typical request-response pattern found in many typical applications.
- Authors
 Andrew Lyon
Andrew Lyon